流式响应的简单处理
虽然现在写这种文章有点晚,但确实还是有一些小伙伴没有处理过打字机效果,在 DeepSeek 爆火的今天,低廉的使用价格、稳定且相对准确的输出效果,想必让不少朋友对能将它集成到自己系统已经有些迫不及待了。
自从 ChatGPT 将打字机式的交互效果带火后,不少朋友都希望在自己的系统中集成这个效果,今天我们就来聊聊这个效果的实现。
首先我们来看下,打字机式的输出与传统的输出有什么区别。
SSE(Server-Sent Events)
在服务器的响应头中,有一个 Content-Type 字段,它告诉浏览器服务器返回的数据类型。一般我们常见的类型有 text/plain、text/html、application/json 等,分别代表纯文本、HTML 和 JSON 数据。我们一般在调用后端接口时,往往会要求后端返回 JSON 字符串,但有时候有些接口可能会有多种内容格式,比如还有代表 xml 的 application/xml 等。当我们在通过程序处理时,便可以根据这个字段来判断服务器返回的数据类型,从而进行不同的解析处理。
text/event-stream 是服务器返回的一种不同于以往的特殊类型,它允许服务器在生成完整响应之前就开始向客户端发送数据,从而提高用户体验,减少首次内容呈现的时间。特别是在处理大型数据集、长时间运行的计算或与 AI 模型交互等场景下,流式响应的优势尤为明显。
它是随着 HTML5 标准引入的一种新的技术,全称是 Server-Sent Events,简称 SSE。它允许客户端向服务端发送一次请求,并维持一个长连接,服务端可以按照 SSE 协议特定的格式分多次向客户端返回数据,直到全部响应内容结束。服务端可以主动关闭连接,也可以向客户端发起一个特殊的结束标识(如 OpenAI 协议中的 [DONE]),由客户端进行关闭。
按照传统的处理方式,假如我们需要在一次请求中从 MySQL 查出 100000 条数据,并返回给前端,我们可能需要把全部数据查出来保存在服务器内存中,然后再给前端返回一个巨大的包,但这无论对前端还是后端来说,这都是一个巨大的负担。而如果使用 SSE 技术,我们可能只需要使用游标的方式,每查询出一小批次的数据就返回一次,无论是前端还是后端或者是数据库,都不会感受到太大的压力。
或者我们需要由后端不停的给前端返回数据,比如股票价格、游戏状态、AI 模型推理结果等。按照传统的方案,我们可能需要使用轮询的方式,每隔一段时间就请求一次后端接口,但这种方式不仅浪费资源,而且用户体验也不好。而如果使用 SSE 技术,我们可能只需要在第一次请求时,后端返回一个流式响应,然后客户端就可以一直保持这个连接,直到后端主动关闭连接。
但这种业务场景其实并不算太多,所以很多人并没有意识到 SSE 的价值,直到 ChatGPT 通过 SSE 技术实现的打字机输出效果,极大的改善了用户在长耗时场景下的等待体验时,大家才重新认识到了 SSE 的重要性。
我们今天的重点不在讨论 SSE 的历史,而是给第一次想要实现打字机效果的朋友一些参考。而且考虑到大家看这篇文章更多的可能是要实现基于 OpenAI 协议格式的流式响应,所以我们将仅以 OpenAI 协议为例,给大家介绍下接入过程。
OpenAI 协议的流式响应格式如下(示例来自 Azure 的 gpt-4o 模型):
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"role":"assistant","content":"","refusal":null},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"你好"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"!"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"有什么"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"我"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"可以"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"帮助"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"你"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"的吗"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"?"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[],"usage":{"prompt_tokens":8,"completion_tokens":9,"total_tokens":17,"prompt_tokens_details":{"cached_tokens":0,"audio_tokens":0},"completion_tokens_details":{"reasoning_tokens":0,"audio_tokens":0,"accepted_prediction_tokens":0,"rejected_prediction_tokens":0}}}
data:[DONE]
在浏览器的 网络 中,我们也能看到这种请求和一般的响应是有区别的,它有一个 EventStream 的标签,可以看到每次服务端返回的响应内容。
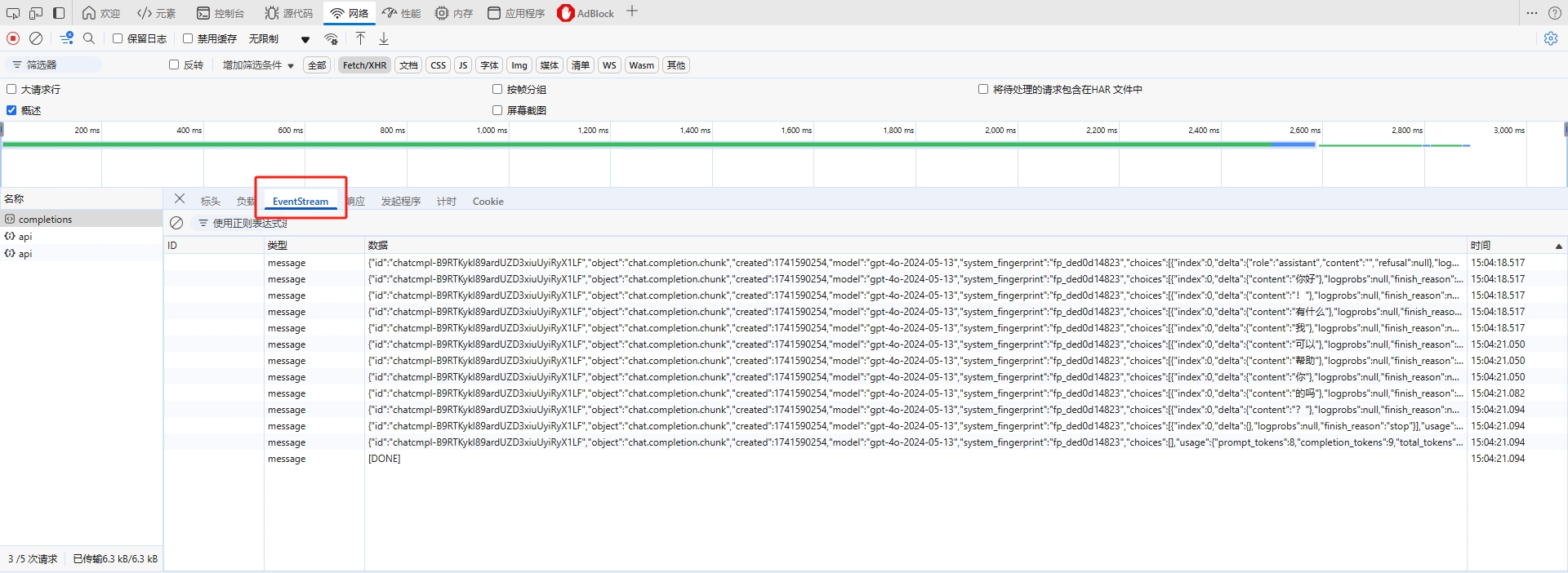
那么怎么才能接收和处理这种数据呢?
目前的主流浏览器都可以使用 EventSource 对象来接收 SSE 响应,但是直接使用 EventSource 是有些复杂,我更建议大家使用更简单的 fetch 方法来实现。
至于 Fetch API 的兼容性,以 Chrome 为例,最早在 42.x (2015 年)的版本便完全支持了这个“新”接口。根据 CanIUse 的统计,在 2017 年 3 月 之后,主流浏览器便都支持了 Fetch API,所以基本可以放心使用。
与一般的请求相似,在发起请求时,代码是没有什么变化的。比如我们给官方的 deepseek-reasoner 模型发送一条“你好”,代码如下:
const response = await fetch("https://api.deepseek.com/v1/chat/completions", {
method: "POST",
headers: {
["Content-Type"]: "application/json",
["Authorization"]: `Bearer YOUR_API_KEY`,
},
body: JSON.stringify({
model: "deepseek-reasoner",
messages: [
{
role: "user",
content: [
{
type: "text",
text: "你好",
},
],
},
],
stream: true,
}),
});
但是当处理请求时,差别就出现了。
我们先看一段代码:
if (!response.ok) {
throw new Error(`HTTP error! status: <span class="katex-error" title="ParseError: KaTeX parse error: Expected 'EOF', got '}' at position 22: …nse.status}`);
}̲
if (!response.…" style="color:#cc0000">{response.status}`);
}
if (!response.body) {
throw new Error("无法获取响应流");
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const text = decoder.decode(value, { stream: true });
// text 就是每次返回的数据
}
这个是标准的 SSE 的响应处理流程。你在循环中拿到的 text 就是每次返回的数据。格式如下:
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"role":"assistant","content":"","refusal":null},"logprobs":null,"finish_reason":null}],"usage":null}
有时候可能会发生多条数据合并的情况,比如:
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"你"},"logprobs":null,"finish_reason":null}],"usage":null}
data:{"id":"chatcmpl-B9RTKykI89ardUZD3xiuUyiRyX1LF","object":"chat.completion.chunk","created":1741590254,"model":"gpt-4o-2024-05-13","system_fingerprint":"fp_ded0d14823","choices":[{"index":0,"delta":{"content":"的吗"},"logprobs":null,"finish_reason":null}],"usage":null}
我们可能需要自己按照 data: 来分割字符串,然后进行处理。但说实话,这样搞很麻烦,还容易出错。
此时我们可以借助一些第三方库,如 eventsource-parser,它可以帮助我们自动分割数据,以简化处理。
# 你也可以使用 yarn 或者 pnpm 等工具来安装
npm install eventsource-parser
然后我们就可以把响应代码换成下面这样:
import { createParser } from "eventsource-parser";
const parser = createParser({
onEvent: (event) => {
if (event.data === "[DONE]") return;
try {
const parsed = JSON.parse(event.data);
if (parsed.error) {
// 当响应内容是一个“错误信息”时,你可以在这里做出相应的处理,如在界面上显示错误信息
return;
}
const content = parsed.choices[0]?.delta?.content || "";
const reasoningContent = parsed.choices[0]?.delta?.reasoning_content || "";
if (content) {
// 你可以在这里处理服务器给出的一般回答
// 比如将 content 追加到 AI 的答案输出部分
}
if (reasoningContent) {
// 你可以在这里处理服务器给出的推理内容(思考的部分)
// 比如将 reasoningContent 追加到 AI 的思考输出部分
}
} catch (e) {
console.error("解析事件数据失败:", e);
}
},
});
// 读取和处理流
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
parser.feed(chunk);
}
你会发现,使用 eventsource-parser 后,它会自动分割数据,并将分割后的数据通过 onEvent 回调函数转交给你来处理,你只需要关注数据本身的情况就行。
对很多用惯了 axios 的小伙伴来说,fetch 有些陌生。不过好在较新版本的 axios 组件也能借助 adapter 机制实现流式响应处理。
使用 Axios
axios 是一个流行的 HTTP 客户端库,它也支持流式响应处理,但需要一些额外的配置。
首先,安装 axios:
npm install axios
考虑到 axios 在 v1.7.0-beta.0 版才引入 fetch 适配器,所以建议你使用的版本至少不要低于该版本,我在一个真实项目中,可以有效处理流式响应的版本号是 1.7.9,所以不放心的话,你也可以安装更新一些的版本。
与 fetch 不同的是,axios 在处理流式响应前,在请求时就要指定流式的配置,代码类似如下:
const response = await axios.post(
"https://api.deepseek.com/v1/chat/completions",
JSON.stringify(
{
model: "deepseek-reasoner",
messages: [
{
role: "user",
content: [
{
type: "text",
text: "你好",
},
],
},
],
stream: true,
},
{
adapter: "fetch",
responseType: "stream",
headers: {
["Content-Type"]: "application/json",
["Authorization"]: "Bearer YOUR_API_KEY",
},
}
)
);
从这里可以看出,我们指定了适配器为 adapter: "fetch",意思是我们将实际使用 fetch API 来发送请求,并指定 responseType: "stream",表示我们希望的响应类型为流。
然后,再使用 axios 处理流式响应:
if (response.status === 200) {
const reader = response.data!.getReader();
const decoder = new TextDecoder();
const parser = createParser({
onEvent: (event) => {
// 这里可以处理每次返回的数据
// 你可以和上文 fetch 一样完成业务逻辑,此处不再赘述
},
});
try {
while (true) {
const { done, value } = await reader!.read();
if (done) break;
parser.feed(decoder.decode(value));
}
} catch (error) {
console.error("Fetch or parsing error:", error);
}
} else {
throw new Error(`HTTP error! status:</span>{response.status}`);
}
尽管我写了两个组件的处理方法,但本质都是在用 fetch API 来发送请求,并处理响应。如果你更习惯使用其他的组件,可以按照类似的思路来实现。
至于如果是在 UI 层面上想要显示出打字机效果,其实就很简单了。因为当你使用流式响应来处理请求时,只要你将更新 UI 的动作放在 onEvent 事件的回调中,那么每当返回一部分数据,你就更新一次 UI(如:在大模型回答的 dom 中追加文字),在用户看起来就会是像打字机输出一样。